
DAM Features
Photography

Here at Asset Bank, we have always held an interest in the potential of Auto Tagging. As you may remember, we looked into the capabilities of AI and image recognition in aiding the addition of metadata to your images. Looking back, we learned that it wasn’t ready to provide enough benefit for a majority of DAM users, but it held a lot of hope.

Things have moved on since then. So much so that we launched a new feature in Asset Bank - Auto Tagging. By integrating with Amazon Rekognition, we were able to harness the power of AI in DAM. This functionality, as you probably guessed, automatically tags keywords to digital assets as they are uploaded into your Asset Bank. We think this is really useful for clients who upload a high volume of images at a time, or for those that have a big data migration exercise on their (lucky) hands!
Whilst we are confident that this new feature is adding value and saving time for our clients, we always know that there is room for us to do better. So, we were thrilled to be approached by academics at the Research Centre for Secure, Usable and Intelligent Systems at the University of Brighton, Karina Rodriguez and Ran Song, who have expertise in visual content and Machine Learning (AI) technologies and are just down the road from us. We started a research project together to explore the scope of AI and DAM, most specifically to understand its potential and current limitations.

Right now, third-party APIs are trained on very generic images that are found on the internet, and have everyday items in them (think mountains, laptops, coffee, beaches, people). Whilst this is useful in many cases, we realise that this becomes a problem for clients dealing with very specific and unique images. This is because AI has not been taught how to classify them.
So, we were aware of the limitations, but we wanted to compare existing AI systems with a system that we custom built. Are these existing products trainable? Can AI recognise abstract concepts if they are trained and exposed to them? These are a few of the questions we were all asking ourselves.
We used data from a variety of sets including one from WaterAid - a client of ours - to compare the systems. These data sets included images containing more complex/specific components. For example, some photos displayed various people smiling. We wanted to see how the systems dealt with detecting smiles, as this is something very intuitive to humans and yet a difficult task for computer vision.
The results explicitly reveal a higher performance in detecting complex concepts from our customised system. This is largely because it was trained with the complex images.
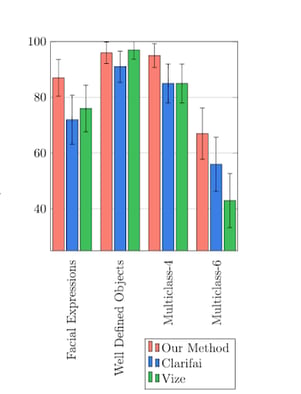
So, by and large, the project confirmed our sneaky suspicions: the available current systems simply are not intelligent enough to deal with specific terms, unique to different clients. You might be thinking ‘why did you embark on this project if you already knew the answer?’. This is a fair point, but it was important that we could make confident conclusions and investigate it further. There is more to it than that though.


This has been an insightful project and it has suggested some possible directions to move toward for future development. We are confident, however, that the AI currently in use still provides substantial benefit for a lot of different clients and audiences.
And one last thing...
Please feel free to read the report on this project if you would like to delve into the details.
